前言
官网,ceph安装
实验环境
通过vagrant搭建4台机器node1~4
其中node1,2,3作node节点,在vagrant创建完的机器后,需要打开virtualbox各新增一块磁盘,sdb。
注意:本实验环境node1,2,3,本文中的node1是deploy机器
vagrantfile如下:
## files: Vagrantfile
# -*- mode: ruby -*-
# vi: set ft=ruby :
hosts = {
"node1" => "192.168.0.11",
"node2" => "192.168.0.12",
"node3" => "192.168.0.13"
}
Vagrant.configure("2") do |config|
config.vm.box = "bento/centos-7.2"
config.vm.box_url = "./vagrant-centos-7.2.box"
config.vm.provider "virtualbox" do |v|
v.customize ["modifyvm",:id,"--memory",3072]
end
hosts.each do |name, ip|
config.vm.define name do |nodes|
nodes.vm.hostname = name
nodes.vm.network :private_network, ip: ip
nodes.vm.provision "shell",
run: "always",
inline: "sudo ifup enp0s8; export LC_ALL=en_US.UTF-8; export LANG=en_US.UTF-8"
end
end
end
ceph-deploy安装
yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
# 配置源,ceph-stable-release变量取值当前稳定版本,如luminous
cat << EOM > /etc/yum.repos.d/ceph.repo
[ceph-noarch]
name=Ceph noarch packages
#baseurl=https://download.ceph.com/rpm-{ceph-stable-release}/el7/noarch
baseurl=https://download.ceph.com/rpm-luminous/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
但是上面这个源,在yum install ceph
[Ceph]
name=Ceph packages for $basearch
baseurl=http://download.ceph.com/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[Ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-mimic/el7/noarch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=http://download.ceph.com/rpm-mimic/el7/SRPMS
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
priority=1
EOM
yum update
yum install ceph-deploy
yum install ntp ntpdate ntp-doc
yum install openssh-server
创建一个ceph deploy user,配置无密码及sudo权限
在每个节点执行
useradd ceph
echo 'ceph' | passwd --stdin ceph
echo "ceph ALL = (root) NOPASSWD:ALL" > /etc/sudoers.d/ceph
chmod 0440 /etc/sudoers.d/ceph
配置sshd可以使用password登录
sed -i 's/PasswordAuthentication no/PasswordAuthentication yes/' /etc/ssh/sshd_config
systemctl reload sshd
配置sudo不需要tty
sed -i 's/Default requiretty/#Default requiretty/' /etc/sudoers
#配置hosts
cat > /etc/hosts<<EOF
192.168.42.100 node1 node1
192.168.42.101 node2 node2
192.168.42.102 node3 node3
EOF
#配免密
#登陆至node1
ssh-keygen
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
#开防火墙端口
#配置完成后,记得service iptables save
#同理,如果是firewalld类似
# ceph moinitor:6789
# ceph OSDS: 6800:7300
#iptables -A INPUT -i {iface} -p tcp -s {ip-address}/{netmask} --dport 6789 -j ACCEPT
或
#firewall-cmd --add-port 6789/tcp --permanent
#或者直接关闭iptables,firewalld,selinx
systemctl stop firewalld && systemctl disable firewalld && setenforce 0
至此,这准备阶段已经完成,现在看下这个部署架构

由于是第一次搭建,先创建一个ceph存储集群:一个moinitor+3个ceph OSD。后续如果要扩展,再加第四个OSD,一个metadata 服务,两个mointor。
部署
mkdir my-cluster
cd my-cluster
#创建cluster,指定hostname
#如果在执行时提示无法找到pkg-packages时,需要yum install python-setuptools -y
ceph-deploy new node1 node2 node3
换国内镜像源
export CEPH_DEPLOY_REPO_URL=http://mirrors.163.com/ceph/rpm-mimic/el7
export CEPH_DEPLOY_GPG_URL=http://mirrors.163.com/ceph/keys/release.asc
配置public网络
#cat ceph.conf#在[global]下面加上
public network = 192.168.52.0/24
cluster network = 192.168.42.0/24
接下来执行ceph-deploy install,换作上面的163源后,安装会很快
#就是在对应结点上,安装 yum install ceph ceph-radosgw -y 这两个包
ceph-deploy install node1 node2 node3
#部署monitor和生成keys
ceph-deploy mon create-initial
#复制配置文件和keyring到node节点,方便执行命令时不用指定monitor地址和keyring
ceph-deploy admin node1 node2 node3
ceph-deploy mgr create node2 #该条命令是Deploy a manager daemon. (Required only for luminous+ builds):
#创建三个osd,所谓osd,即存储介质,
ceph-deploy osd create --data /dev/sdb node2
ceph-deploy osd create --data /dev/sdb node3
ceph-deploy osd create --data /dev/sdb node4
#以下,如果在执行健康检查时候,一直没有health_ok,基本上就是时钟不对,需要开启时钟同步。
- 创建osd及批量创建osd脚本
在创建OSD时,要查看系统的磁盘,每块磁盘创建一个OSD,但是若是有盘有分区表DPT,在执行ceph-deploy osd create就会失败,需要dd掉,可通过以下脚本全部删除分区后,直接创建osd;该脚本的实用场景:1.系统分区做了raid,即没有分区表,而其他的盘都有分区,即磁盘为/dev/sdb,则分区为/dev/sdb1,而系统盘/dev/sda则没有分区。
查看系统有没有raidcat /proc/mdstat#!/bin/bash set -e cp /tmp/osd3.txt /tmp/osd3.txt.bak rm -rf /tmp/osd3.txt for i in `lsblk -l|grep sd | awk -F' ' '{print $1}'|grep 1|tr -d '1'`;do echo $i >> /tmp/osd3.txt;done for i in `cat /tmp/osd3.txt`;do dd if=/dev/zero of=/dev/$i bs=512k count=1; ceph-deploy osd create --data /dev/$i node1;done - 在执行ceph-deploy mon create-initial时提示
monitor is not yet in quorum,则很有可能是时钟没同步,或是时区不一致 - 造成集群状态health_warn:clock skew detected on mon节点的原因有两个,一个是mon节点上ntp服务器未启动,另一个是ceph设置的mon的时间偏差阈值比较小
#vi ~/my-cluster/ceph.conf #在global字段下添加: mon clock drift allowed = 2 mon clock drift warn backoff = 30 #ceph-deploy --overwrite-conf config push node{1..3} #systemctl restart ceph-mon.target #ceph -s安装ntp,两两相互同步
# yum install ntpd # cat /etc/ntp.conf driftfile /var/lib/ntp/ntp.drift server 192.168.52.94 burst iburst server 192.168.52.98 burst iburst server 127.127.1.0 fudge 127.127.1.0 stratum 11 - yum缓存文件的使用
/etc/yum.conf配置文件,设置"keepcache=1"配置文件中的”cachedir”就是用来缓存安装包的具体目录。
待A服务器完成所有配置后,将cachedir指定的目录直接拷贝到其它待安装的服务器上,然后使用”yum -C install [软件包名]”即可使用缓存安装。(-C参数表示使用系统缓存)。
- 结果
[root@node1 my-cluster]# ceph -s cluster: id: 1165a001-9c43-4f7a-8f51-a8aad26a5c04 health: HEALTH_OK services: mon: 3 daemons, quorum node2,node3,node1 mgr: node2(active), standbys: node3, node1 osd: 72 osds: 72 up, 72 in data: pools: 0 pools, 0 pgs objects: 0 objects, 0 B usage: 75 GiB used, 524 TiB / 524 TiB avail pgs: - ceph-deploy install 其实就是在对应结点上,安装 ceph ceph-radosgw 这两个包,可直接配置ceph的yum源,配置163的源
[ceph] name=Ceph packages for $basearch baseurl=http://mirrors.163.com/ceph/rpm-mimic/el7/$basearch enabled=1 gpgcheck=1 priority=1 type=rpm-md gpgkey=http://mirrors.163.com/ceph/keys/release.asc [ceph-noarch] name=Ceph noarch packages baseurl=http://mirrors.163.com/ceph/rpm-mimic/el7/noarch enabled=1 gpgcheck=1 priority=1 type=rpm-md gpgkey=http://mirrors.163.com/ceph/keys/release.asc [ceph-source] name=Ceph source packages baseurl=http://mirrors.163.com/ceph/rpm-mimic/el7/SRPMS enabled=0 gpgcheck=1 type=rpm-md gpgkey=http://mirrors.163.com/ceph/keys/release.asc priority=1 - Yum从光盘安装
yum --disablerepo=\* --enablerepo=c7-media install -y ntp
清理集群
#至此,如果安装失败,需要清除,重新开始
ceph-deploy purge node2 node3 node4
ceph-deploy purgedata node2 node3 node4
ceph-deploy forgetkeys
rm ceph.* -rf
yum remove librados2 libradosstriper1 -y
ceph-deploy purge node2 node3 node1 && ceph-deploy purgedata node2 node3 node1 && ceph-deploy forgetkeys && rm ceph.* -rf
扩展
基础的集群搭建完成后,需要扩展。在node2上增加一个metadata server,在node3和node4上加一个ceph monitor和manager;增加高可靠

#如果要用cephFS,即如果要用文件存储,需要安装这个mds
ceph-deploy mds create node2
#加Monitor,高可用需要,Paxos算法
ceph-deploy mon add node3
ceph-deploy mon add node1
#如果你加了ceph mointor,ceph将开始同步多个Monitor之间的数据,检查monitors状态
ceph quorum_status --format json-pretty
#增加managers,主从模式
ceph-deploy mgr create node3 node1
#查看standby manager,其实是查看ceph,所有的参数。
ssh node2 sudo ceph -s
#增加一个RGW 实例,监听7480
ceph-deploy rgw create node2
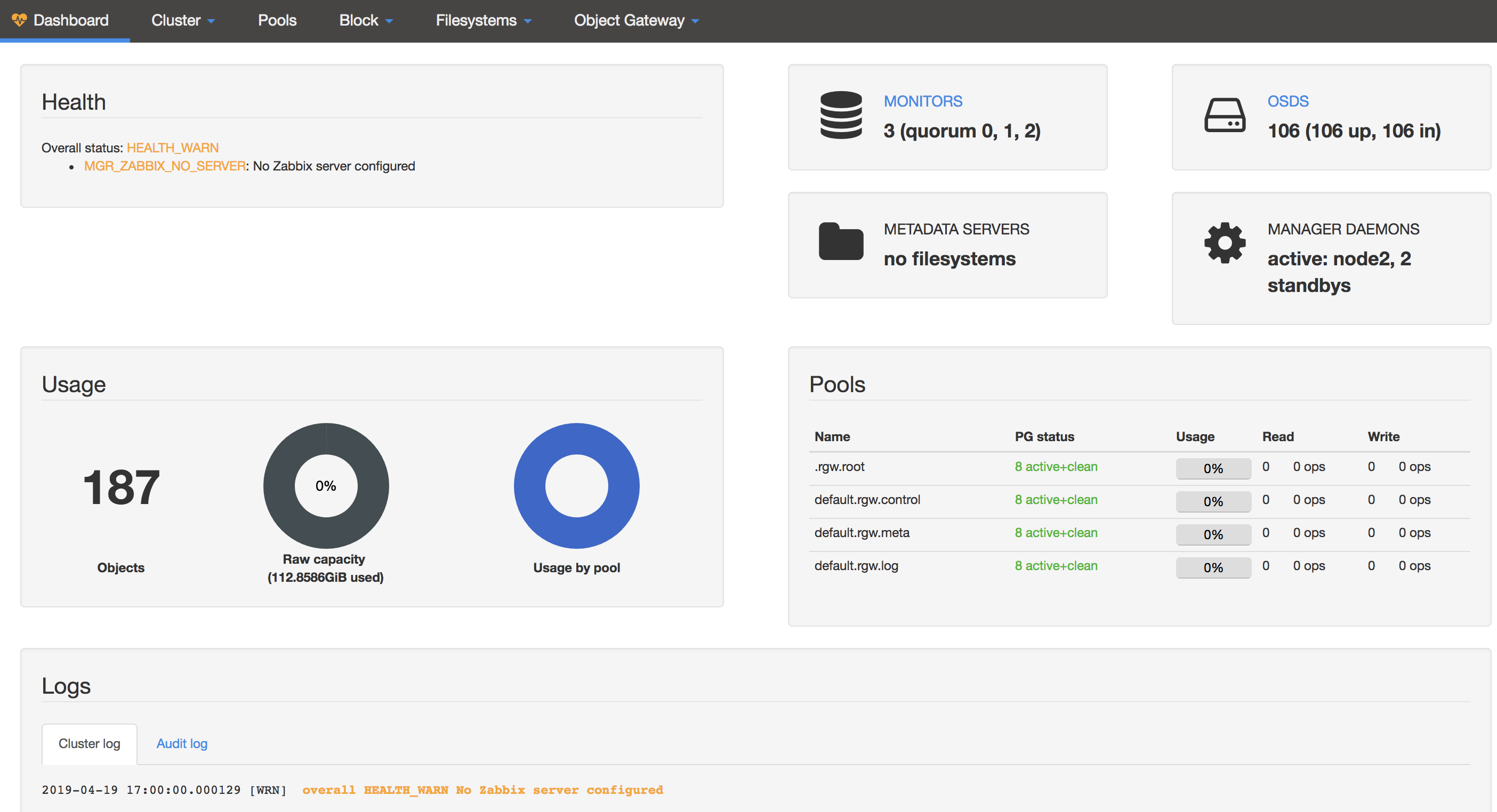
开启dashboard
- 生成并安装自签名的证书
# ceph dashboard create-self-signed-cert - 生成key pair,并配置给ceph mgr
# mkdir mgr-dashboard && cd mgr-dashboard/ # openssl req -new -nodes -x509 -subj "/O=IT/CN=ceph-mgr-dashboard" -days 3650 -keyout dashboard.key -out dashboard.crt -extensions v3_ca Generating a 2048 bit RSA private key # ls dashboard.crt dashboard.key $ ceph config-key set mgr/dashboard/crt -i dashboard.crt $ ceph config-key set mgr/dashboard/key -i dashboard.key # ceph mgr module disable dashboard # ceph mgr module enable dashboard注意,要是不要想https可以关闭
ceph config set mgr mgr/dashboard/ssl false - 在ceph active mgr上配置server addr和port
若使用默认的8443端口,则可跳过该步骤!# ceph config set mgr mgr/dashboard/server_addr 192.168.52.95 # 若要配置成默认的,则可以随ceph mgr的节点漂移时发生变化,尽量用默认 # ceph config set mgr mgr/dashboard/server_addr :: # ceph config set mgr mgr/dashboard/server_port 8443 # ceph mgr services - 生成登陆认证的用户名和密码
# ceph dashboard set-login-credentials root fitstore - 如果是跳板机,需要配置端口转发
ssh -Nf -L 0.0.0.0:8444:192.168.52.95:8443 <跳板机IP> 或者 ssh -C -f -N -g -L 0.0.0.0:8443:192.168.52.98:8443 10.128.151.1
存取对象数据
在集群里面存一个对象数据,必须设置一个对象名字、指定一个pool。客户端检索最新的集群地图并通过CRUSH算法计算出对象到placement group的映射关系,并且动态计算出placement group到OSD之间的绑定。因此如果要找到对象的位置,你只需要知道object name及pool name
echo {Test-data} > testfile.txt
ceph osd pool create mytest 8
rados put {object-name} {file-path} --pool=mytest
rados put test-object-1 testfile.txt --pool=mytest
rados -p mytest ls
ceph osd map {pool-name} {object-name}
ceph osd map mytest test-object-1
实验如下:
echo "fuck fuck!!" > testfile.txt
#创建pool
[root@node2 ~]# ceph osd pool create mytest 8
pool 'mytest' created
#rados put {object name} {file-path} --pool=mytest,存数据
[root@node2 ~]# rados put test-object-1 testfile.txt --pool=mytest
#查看对应pool里的数据
[root@node2 ~]# rados -p mytest ls
test-object-1
#查看它的映射关系
[root@node2 ~]# ceph osd map mytest test-object-1
osdmap e31 pool 'mytest' (5) object 'test-object-1' -> pg 5.74dc35e2 (5.2) -> up ([1,0,2], p1) acting ([1,0,2], p1)
#删除Mytest pool,需要删除两次,让你确认。
[root@node2 ~]# ceph osd pool rm mytest
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool mytest. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
[root@node2 ~]# ceph osd map mytest test-object-1
osdmap e31 pool 'mytest' (5) object 'test-object-1' -> pg 5.74dc35e2 (5.2) -> up ([1,0,2], p1) acting ([1,0,2], p1)
#将node1作为测试的机器,在上面先装上ceph
ceph-deploy install node1
ceph-deploy admin node1
这样,node1上就可以对集群执行操作,而不用每次登陆至集群,如
[ceph@node1 my-cluster]$ ssh node2 sudo ceph -s
cluster:
id: 35d6c678-5ee5-4741-a3eb-cbad9359d990
health: HEALTH_OK
services:
mon: 3 daemons, quorum node2,node3,node4
mgr: node2(active), standbys: node3, node4
osd: 3 osds: 3 up, 3 in
data:
pools: 4 pools, 32 pgs
objects: 219 objects, 1.1 KiB
usage: 3.0 GiB used, 21 GiB / 24 GiB avail
pgs: 32 active+clean
掘金上的这篇文章写得也比较好,可以参考 至此,环境初步搭建完毕,如下为搭建三个不同存储方式的步骤。
文件存储

官方建议ceph10.x(Jewel)就开始要使用4.x的kernal。
创建文件系统,创建之前mds是standby的,创建之后才是active的
#创建一个pool 64个pg
[root@node2 ~]# ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created
[root@node2 ~]# ceph fs new cephfs_my cephfs_metadata cephfs_data
new fs with metadata pool 7 and data pool 6
[root@node2 ~]# ceph fs ls
name: cephfs_my, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@node2 ~]# ceph mds stat
cephfs_my-1/1/1 up {0=node2=up:active}
给要挂载目录的机器创建认证keyring
[root@node2 ceph]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQBthX9cG7m4GRAAnkylL1zxJCE9NmBrnkrTXQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
以上key的值 AQBthX9cG7m4GRAAnkylL1zxJCE9NmBrnkrTXQ== 保存到空白文件,以admin.secret来命名,放到要挂载的目标机器上,然后登陆到这个机器上,执行挂载
[root@node1 ceph]# mount -t ceph 192.168.0.12:6789:/ /mnt/mycephfs/ -o name=admin,secret=AQBthX9cG7m4GRAAnkylL1zxJCE9NmBrnkrTXQ==
提示挂载不上,看/var/log/messages日志,提示如下错误
Mar 15 12:07:19 node1 kernel: libceph: mon0 192.168.0.12:6789 feature set mismatch, my 103b84a842aca < server's 40103b84a842aca, missing 400000000000000
Mar 15 12:07:19 node1 kernel: libceph: mon0 192.168.0.12:6789 missing required protocol features
google该错误,经查是内核版本不支持某特性,提示用命令禁止
ceph osd crush tunables hammer
然后再挂载就正常,原因分析为
[root@node1 ceph]# lsmod |grep rbd
rbd 73158 0
libceph 244999 2 rbd,ceph
[root@node1 ceph]# uname -a
Linux node1 3.10.0-327.4.5.el7.x86_64 #1 SMP Mon Jan 25 22:07:14 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
这个rbd是内核的,由于内核版本低不支持新的特性,而ceph很多新的特性,看提示的报错信息及code值,禁止这个特性就能挂载成功;另外一种方法是用fuse这个方法,fuse是用户态的,不用内核,虽然性能赶不上内核的rbd,但是在用户态,能够很方便的与ceph社区保持一致并友好更新
块存储
#在admin节点上,用ceph工具创建一个pool,建议用rbd
#在admin节点,用rbd工具对pool作初始化
rbd pool init <pool-name>
# 创建block device image
#rbd create foo --size 4096 --image-feature layering [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
#映射image到block device
sudo rbd map foo --name client.admin [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
#用块设备创建文件系统
sudo mkfs.ext4 -m0 /dev/rbd/{pool-name}/foo
#挂载
sudo mkdir /mnt/ceph-block-device
sudo mount /dev/rbd/{pool-name}/foo /mnt/ceph-block-device
cd /mnt/ceph-block-device
#最后,实现开机自动挂载
对象存储
Gateway daemon内嵌了一个civeweb,所以你不用再去安装web server或是配置FastCGI。另外,ceph-deploy可以跟你安装gateway包,生成key,配置数据目录并为你创建一个网关实体。
网络端口:默认7480,防火墙要开此端口
要开启一个ceph object gateway,有以下步骤:
- 安装ceph object gateway
在admin节点的工作目录ceph-deploy install --rgw node2 - 创建一个object gateway instance
ceph-depy rgw create node2发现在执行第一步的时候,实例已经创建并已经开启了7480端口,可检查这个端口,并url访问 http://192.168.0.12:7480,如下: ```xml
3. 配置实例:如要修改默认端口
在node2节点的/etc/ceph/ceph.conf下,新加section如
[client.rgw.node2] rgw_frontends=”civetweb port=80”
然后重启rgw服务
systemctl restart ceph-radosgw@rgw.node2.service ``` 然后查看80端口是否被监听,并访问80端口看效果。