- 架构概览
- Item Pipeline
- 编写你的item pipeline
- Feed exports
- Link Extractors
- logging
- 数据收集(Stats Collection)
- 发送email
- Telnet终端(Telnet Console)
- Web Service
- 常见问题(FAQ)
- 避免被禁止(ban)
- 性能测试
- 关于scrapy解析需用的几个库
架构概览
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述
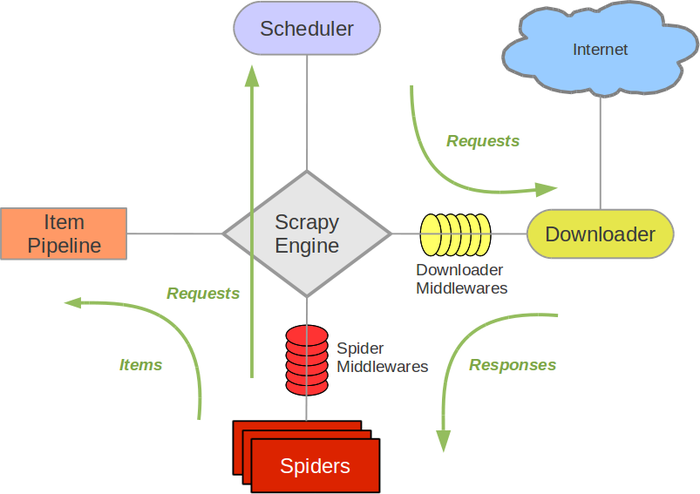
Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理,每个item pipeline组件是实现了简单方法的python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据,检查item包含某些字段
- 查重并丢弃
- 将爬取结果保存到数据库中
编写你的item pipeline
每个item pipeline都是一个独立的python类
process_item(item,spider)
# item: Item对象,被爬取的item
# spider: Spider对象,被爬取该item的spider
每个item pipeline都需要调用该方法,这个方法必须返回一个item对象,或是抛出DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
也可以实现以下方法:
open_spider(spider) # 当spider开启时,这个方法被调用
close_spider(spider) # 当spider关闭时,这个方法被调用
样例
- 验证价格,同时丢弃没有价格的item
让我们来看一下以下这个假设的pipeline,它为那些不含税(price_excludes_vat 属性)的item调整了 price 属性,同时丢弃了那些没有价格的item:
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
- 将item写入JSON文件
以下pipeline将所有(从所有spider中)爬取到的item,存储到一个独立地 items.jl 文件,每行包含一个序列化为JSON格式的item:
import json
class JsonWriterPipeline(object):
def __init__(self):
self.file = open('items.jl', 'wb')
def process_item(self, item, spider):
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
return item
JsonWriterPipeline的目的只是为了介绍怎样编写item pipeline,如果你想要将所有爬取的item都保存到同一个JSON文件, 你需要使用 Feed exports 。
- 去重
一个用于去重的过滤器,丢弃那些已经被处理过的item。让我们假设我们的item有一个唯一的id,但是我们spider返回的多个item中包含有相同的id:
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
- 启用一个Item Pipeline组件
为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES 配置,就像下面这个例子:
ITEM_PIPELINES = {
'myproject.pipelines.PricePipeline': 300,
'myproject.pipelines.JsonWriterPipeline': 800,
}
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
Feed exports
实现爬虫时最经常提到的需求就是能合适的保存爬取到的数据,或者说,生成一个带有爬取数据的”输出文件”(通常叫做”输出feed”),来供其他系统使用。scrapy自带了Feed输出,并且支持多种序列化格式及存储方式。
序列化方式
feed输出使用到item exporters。其自带支持类型有:
- JSON:使用JsonItemExplorter
- JSON lines: JsonLinesItemExporter
- CSV: CsvItemExporter
- XML: XmlItemExporter
- Pickle: PickleItemExporter
- Marshal: MarshaItemExporter
存储storages
使用feed存储时通过使用URI(通过FEED_URI设置)来定义存储端。feed支持URI支持方式支持的多种存储后端类型。
- 本地文件系统 将feed存储在本地系统,URI scheme: file,URI样例: file:///tmp/export.csv;注意: (只有)存储在本地文件系统时,您可以指定一个绝对路径 /tmp/export.csv 并忽略协议(scheme)。不过这仅仅只能在Unix系统中工作。
scrapy runspider quotes_spider.py -o quotes.json
- FTP 将feed存储在FTP服务器。URI scheme: ftp URI样例: ftp://user:pass@ftp.example.com/path/to/export.csv
- S3(需要boto) URI scheme: s3 URI样例: s3://mybucket/path/to/export.csv s3://aws_key:aws_secret@mybucket/path/to/export.csv 需要的外部依赖库: boto 将feed存储在 Amazon S3 。
- 标准输出 eed输出到Scrapy进程的标准输出。 URI scheme: stdout; URI样例: stdout:
设定settings
这些是配置feed输出的设定
- FEED_URI (必须)
- FEED_FORMAT:输出feed的序列化格式
- FEED_STORAGES
- FEED_EXPORTERS
- FEED_STORE_EMPTY
Link Extractors
Link Extractors 是那些目的仅仅是从网页(scrapy.http.Response 对象)中抽取最终将会被follow链接的对象。
Scrapy默认提供2种可用的 Link Extractor, 但你通过实现一个简单的接口创建自己定制的Link Extractor来满足需求。
每个LinkExtractor有唯一的公共方法是 extract_links ,它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。Link Extractors,要实例化一次并且 extract_links 方法会根据不同的response调用多次提取链接。
Link Extractors在 CrawlSpider 类(在Scrapy可用)中使用, 通过一套规则,但你也可以用它在你的Spider中,即使你不是从 CrawlSpider 继承的子类, 因为它的目的很简单: 提取链接。
logging
Scrapy提供了log功能。您可以通过 scrapy.log 模块使用。当前底层实现使用了 Twisted logging ,不过可能在之后会有所变化。
log服务必须通过显示调用 scrapy.log.start() 来开启。
- CRITICAL - 严重错误(critical)
- ERROR - 一般错误(regular errors)
- WARNING - 警告信息(warning messages)
- INFO - 一般信息(informational messages)
- DEBUG - 调试信息(debugging messages)
您可以通过终端选项(command line option) –loglevel/-L 或 LOG_LEVEL 来设置log级别。
from scrapy import log
log.msg("This is a warning", level=log.WARNING)
scrapy.log模块
scrapy.log.start(logfile=None, loglevel=None, logstdout=None) # 启动log功能。该方法必须在记录(log)任何信息前被调用。否则调用前的信息将会丢失
scrapy.log.msg(message, level=INFO, spider=None) # 记录信息(Log a message)
scrapy.log.CRITICAL
数据收集(Stats Collection)
发送email
虽然Python通过 smtplib 库使得发送email变得很简单,Scrapy仍然提供了自己的实现。 该功能十分易用,同时由于采用了 Twisted非阻塞式(non-blocking)IO ,其避免了对爬虫的非阻塞式IO的影响。 另外,其也提供了简单的API来发送附件。 通过一些 settings 设置,您可以很简单的进行配置。有两种方法可以创建邮件发送器(mail sender)
- 通过标准构造器(constructor)创建:
from scrapy.mail import MailSender mailer = MailSender() - 您可以传递一个Scrapy设置对象,其会参考 settings:
mailer = MailSender.from_settings(settings)
这是如何来发送邮件了(不包括附件):
mailer.send(to=["someone@example.com"], subject="Some subject", body="Some body", cc=["another@example.com"])
Telnet终端(Telnet Console)
Scrapy提供了内置的telnet终端,以供检查,控制Scrapy运行的进程。 telnet仅仅是一个运行在Scrapy进程中的普通python终端。因此您可以在其中做任何事。
telnet localhost 6023
telnet为了方便提供了一些默认定义的变量:
快捷名称 描述
crawler Scrapy Crawler (scrapy.crawler.Crawler 对象)
engine Crawler.engine属性
spider 当前激活的爬虫(spider)
slot the engine slot
extensions 扩展管理器(manager) (Crawler.extensions属性)
stats 状态收集器 (Crawler.stats属性)
settings Scrapy设置(setting)对象 (Crawler.settings属性)
est 打印引擎状态的报告
prefs 针对内存调试 (参考 调试内存溢出)
p pprint.pprint 函数的简写
hpy 针对内存调试 (参考 调试内存溢出)
Web Service
Scrapy提供用于监控及控制运行中的爬虫的web服务(service)。 服务通过 JSON-RPC 2.0 协议提供大部分的资源,不过也有些(只读)资源仅仅输出JSON数据。
常见问题(FAQ)
- Q:Scrapy相BeautifulSoup或lxml比较,如何呢?
BeautifulSoup 及 lxml 是HTML和XML的分析库。Scrapy则是 编写爬虫,爬取网页并获取数据的应用框架(application framework)。
Scrapy提供了内置的机制来提取数据(叫做 选择器(selectors))。 但如果您觉得使用更为方便,也可以使用 BeautifulSoup (或 lxml)。 总之,它们仅仅是分析库,可以在任何Python代码中被导入及使用。
拿Scrapy与 BeautifulSoup (或 lxml) 比较就好像是拿 jinja2 与 Django 相比。
- Q: Scrapy支持那些Python版本?
Scrapy仅仅支持Python 2.7。 Python2.6的支持从Scrapy 0.20开始被废弃了。Scrapy不支持Python 3但已经在计划中
- Q: 我要如何在spider里模拟用户登录呢?
参考 使用FormRequest.from_response()方法模拟用户登录. http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/request-response.html#topics-request-response-ref-request-userlogin
- Q: Scrapy是以广度优先还是深度优先进行爬取的呢?
默认情况下,Scrapy使用 LIFO 队列来存储等待的请求。简单的说,就是 深度优先顺序 。深度优先对大多数情况下是更方便的。如果您想以 广度优先顺序 进行爬取,你可以设置以下的设定:
DEPTH_PRIORITY = 1
SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
- Q: 为什么Scrapy下载了英文的页面,而不是我的本国语言?
尝试通过覆盖 DEFAULT_REQUEST_HEADERS 设置来修改默认的 Accept-Language 请求头。
- Q:将所有爬取到的item转存(dump)到JSON/CSV/XML文件的最简单的方法?
scrapy crawl myspider -o items.json
scrapy crawl myspider -o items.json
scrapy crawl myspider -o items.xml
- Q:分析大XML/CSV数据源的最好方法是?
使用XPath选择器来分析大数据源可能会有问题。选择器需要在内存中对数据建立完整的 DOM树,这过程速度很慢且消耗大量内存。
为了避免一次性读取整个数据源,您可以使用 scrapy.utils.iterators 中的 xmliter 及 csviter 方法。 实际上,这也是feed spider(参考 Spiders)中的处理方法。
- Scrapy自动管理cookies么?
是的,Scrapy接收并保持服务器返回来的cookies,在之后的请求会发送回去,就像正常的网页浏览器做的那样。
避免被禁止(ban)
下面是些处理这些站点的建议(tips):
- 使用user agent池,轮流选择之一来作为user agent。池中包含常见的浏览器的user agent(google一下一大堆)
- 禁止cookies(参考 COOKIES_ENABLED),有些站点会使用cookies来发现爬虫的轨迹。
- 设置下载延迟(2或更高)。参考 DOWNLOAD_DELAY 设置。
- 如果可行,使用 Google cache 来爬取数据,而不是直接访问站点。
- 使用IP池。例如免费的 Tor项目 或付费服务(ProxyMesh)。
- 使用高度分布式的下载器(downloader)来绕过禁止(ban),您就只需要专注分析处理页面。这样的例子有: Crawlera http://crawlera.com/
性能测试
scrapy bench
关于scrapy解析需用的几个库
selenium
urllib
Beautifulsoup
import requests
from bs4 import BeautifulSoup
url = "https://tieba.baidu.com/index.html"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html,'lxml')
content = soup.find_all(class_="title feed-item-link")
#获取title
title = []
href = []
for item in content:
title.append(item.text)
href.append(item.attrs['href'])
for i in zip(title,href):
print(i)